- Court Street Data
- Posts
- Keeping Up with the Technologies
Keeping Up with the Technologies
An attempt to stay focused when technology tries to outrun you.
William DeCesare
October 30, 2025

It’s an interesting time to work in tech.
A year ago, I wrote about using Cursor to rebuild my personal website. It was my foray into vibe coding, and while not a flawless experience, I felt invincible. The days of spending hours searching for specific functions or managing package dependencies to launch an app were over. All I needed was $20 per month and a head full of ideas.
Fast forward to today, and keeping up with tech advancements is more challenging than ever.
The impetus behind this post was to test Claude Code. I’d heard great things about how well it integrates into an IDE and developer workflow, while natively providing model context. This is counter to the original Cursor workflow of manually selecting files to inform each model prompt.1 Lo and behold, in my initial search for Claude Code, I discovered that OpenAI released Codex, its own IDE-embedded agent. And down the rabbit hole I went…
A variety of questions floated in my mind:
Is Claude Code still the leader? Or is Codex the way to go? Wait, Cursor launched its own Agent workflow on top of Anthropic and OpenAI models. So, Cursor uses more models… does that improve product quality? What about Windsurf and Bolt - how do these IDEs differ from Cursor?
My brain was like a pinball bouncing between shiny new tools, unable to stay focused in one lane. This feeling had me thinking about a more recent trend in data… the era of cloud transformation.
History Doesn’t Repeat Itself, But It Often Rhymes
I entered the data space a bit later than the cloud transformation era, but I imagine folks had similar questions during the nascent days of Redshift, Azure, Snowflake, and BigQuery. Days of executives pushing cloud migration to try and create a strategic advantage over competition, and IT teams trying to parse the minute differences between managed OLAP databases.
However, there are a few stark differences between the cloud transformation era and today’s AI revolution:
The tech is upgrading significantly. A data warehouse is a data warehouse. You can improve configuration abilities, add more integrations, and upgrade the developer experience. However, outside of compute efficiency gains, I argue that the baseline technology (i.e., an OLAP system) has not experienced significant change, and the decision framework is driven by developer experience and preference. Meanwhile, model benchmarks are improving at step-wise functions and integrating into all parts of our physical and digital lives.
The tech is accelerating at a faster rate. OpenAI released ChatGPT to the public on November 30th, 2022. In the three years since, the following features have been released: RAG (Retrieval-Augmented Generation), MCP (Model Context Protocol), and agentic workflows. Not to mention at least seven companies scaled from $0M to $100M+ in ARR.2
Vertical gains influence the decision-making process. Already host your app on AWS? Might as well stay in the Amazon ecosystem and choose Redshift. This dynamic of vendor lock-in no longer applies, or at least not yet, when choosing models and AI-powered tools. It’s relatively simple to plug in different models into any workflow, especially with the rise of wrappers like LangChain.
Competition is Good, Right?
A downside of AI abundance is that it stokes fear of being left behind. Technologists, particularly those in the data community, fear that not knowing the latest and greatest tools puts their roles at risk or makes them less competitive in the job market.
You might be thinking, "Luddite view incoming." Not the case! I’m a proponent of increasing operational efficiency in the workplace through competition. Competition drives better products for end users, and I see it as a way to propel product growth and push society into the future.
But, this still doesn’t erase the fear…

Thus, how do we assuage these fears? One approach to not being left behind is to, well, learn every tool at your disposal.
In most cases, this is a terrible idea. You’ll spend more time installing the software and entering payment info on a Stripe checkout page than actually evaluating and learning the product. Garnering expertise in different technologies is time-consuming, even without the rapid development of these tools.
A more prudent approach? Pick one and start building.
Most of the time, the tool you choose does not matter; the experience is translatable across products. Worrying about choosing the next big technology to form expertise will lead to decision paralysis. Perfection is the enemy of progress.
There’s a famous Teddy Roosevelt quote that goes something like:
"In any moment of decision, the best thing you can do is the right thing, the next best thing is the wrong thing, and the worst thing you can do is nothing.”
Drawing a line in the sand: Codex
I find myself using ChatGPT over Claude for basic coding questions and tasks. I’m not suggesting that Claude is worse, but ChatGPT is good (and sometimes great) enough not to warrant a switch. As a result, I stayed within the ChatGPT ecosystem3 and leveraged Codex to build an MVP for courtstreetdata.com (not yet live, but soon 😄). I want to expand Court Street Data’s marketing reach and showcase case studies; a website is a low-lift way to do so.
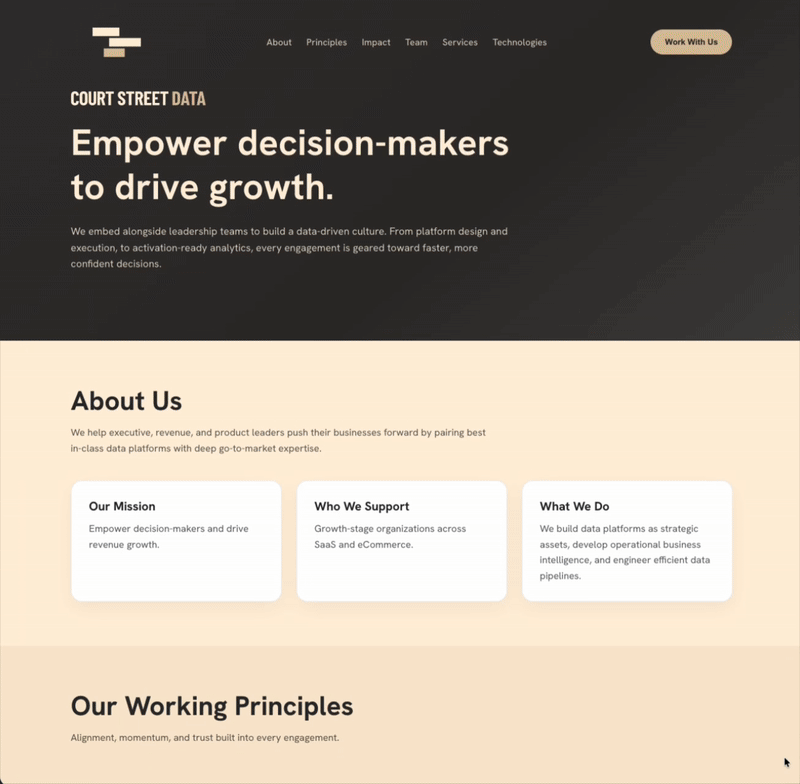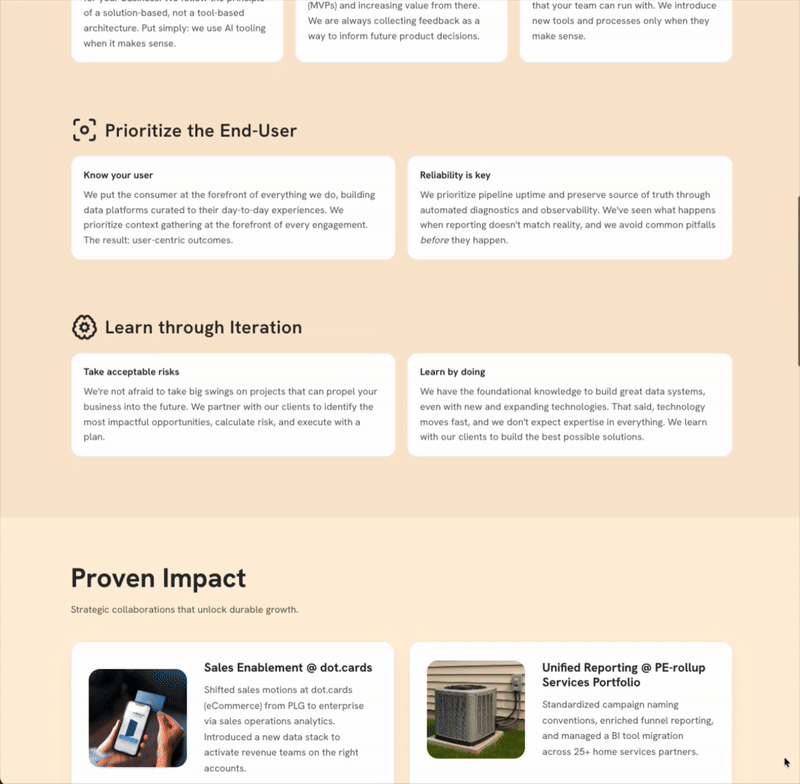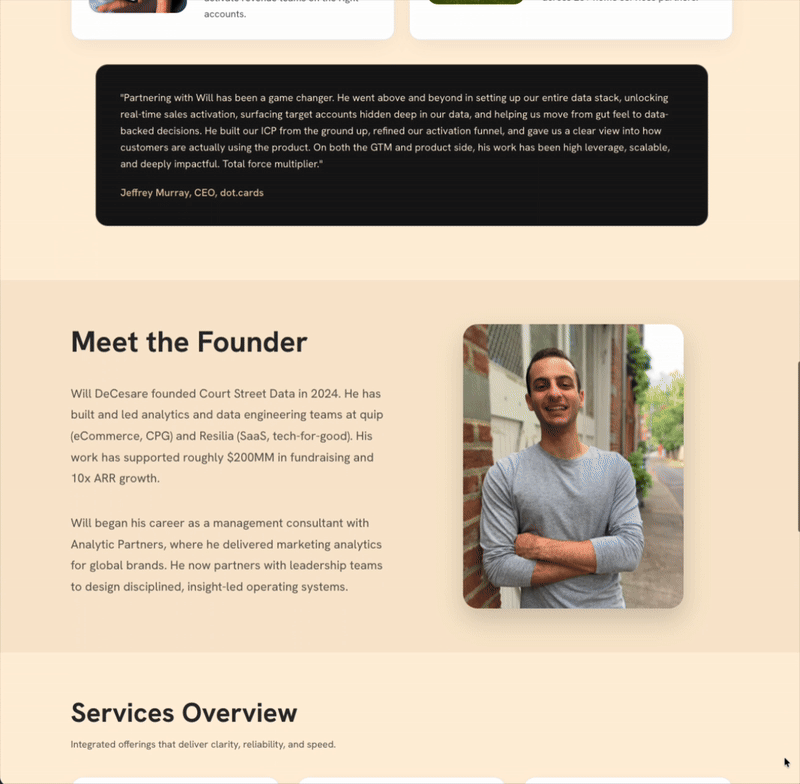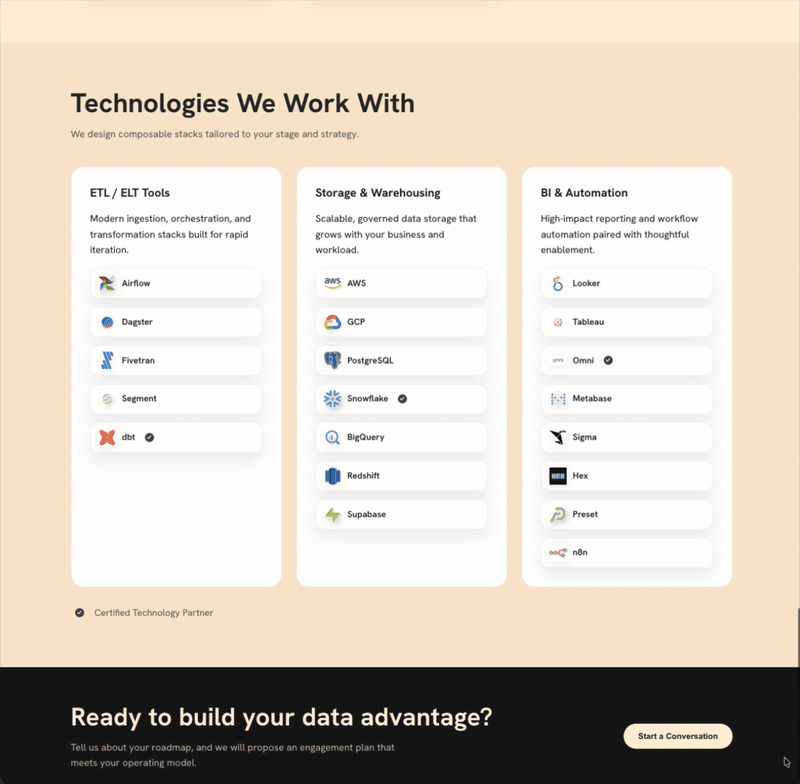
While it still needs a few finishing touches, the application is built and hosted with the help of Codex.
There are a few takeaways from my experience so far:
Before, you were the product manager and the engineer. Now, you’re only the product manager.
One year ago, the Cursor workflow went something like this:
Add files to the context window
Ask Cursor how to change a feature
Cursor suggests code recommendations
Accept code recommendation
Refresh the page for QA
Though preferable to endlessly combing through Stack Overflow like an encyclopedia, the workflow was clunky and manual.
Now, however, Codex is my full-stack engineer. Outside of marketing copy, I can count the number of times I manually changed code on one hand. The new workflow involved inputting descriptions of what needed to be done, refreshing the app to ensure they were completed, and moving on to the next item.
Codex thinks hard to produce better results
When building my personal website, I spent most of my time on UX/UI updates. When building the local version of Court Street Data’s site, I spent most of my time on copy - Codex generated its own copy that needed to be improved or removed altogether - rather than actual technical efforts.
Whether this is a function of overall model improvement or the introduction of agents is left unknown, but regardless, it’s pleasing to know that I no longer need to go twelve rounds in an AI chat to implement a simple hamburger option menu. I could now assume correctness and quality check for errors, while the same could not be said of the previous workflow.
That said, the average response time was about thirty seconds per outcome. This surprised me given the simplicity of the application’s code base, but it makes sense given that the model takes more context into account before delivering and executing an action plan.
Codex reacts well to ambiguity
There were two relatively complex pieces of the website build that I was unsure Codex would be able to handle well.
The first was networking with NameCheap, where I purchased the domain, and ensuring compatibility with Railway, where the app is hosted. However, I encountered zero issues with compatibility.
The second was instrumenting a contact form submission. One simple prompt and about ninety seconds later, I was able to collect contact form submissions with an embedded Fillout widget.
Update those buttons such that when they are clicked, this Fillout popup opens: [Fillout HTML]
With some surprise, it handled both with ease, even providing Railway environment variables along the way. TLDR: It was driving decisions outside of the application platform.
Closing Thoughts
Will Codex be dethroned next month? Probably. But 100 times out of 100, building anything is better than thinking about building something. So I’ll keep building, but it just might be slower than the release notes come out.
1 Cursor upgraded their use of context as well.
2 OpenAI, Anthropic, Cursor, Lovable, Perplexity, Midjourney, and ElevenLabs.
3 Maybe it’s closer to the shift to cloud data warehousing than we thought…
Reply